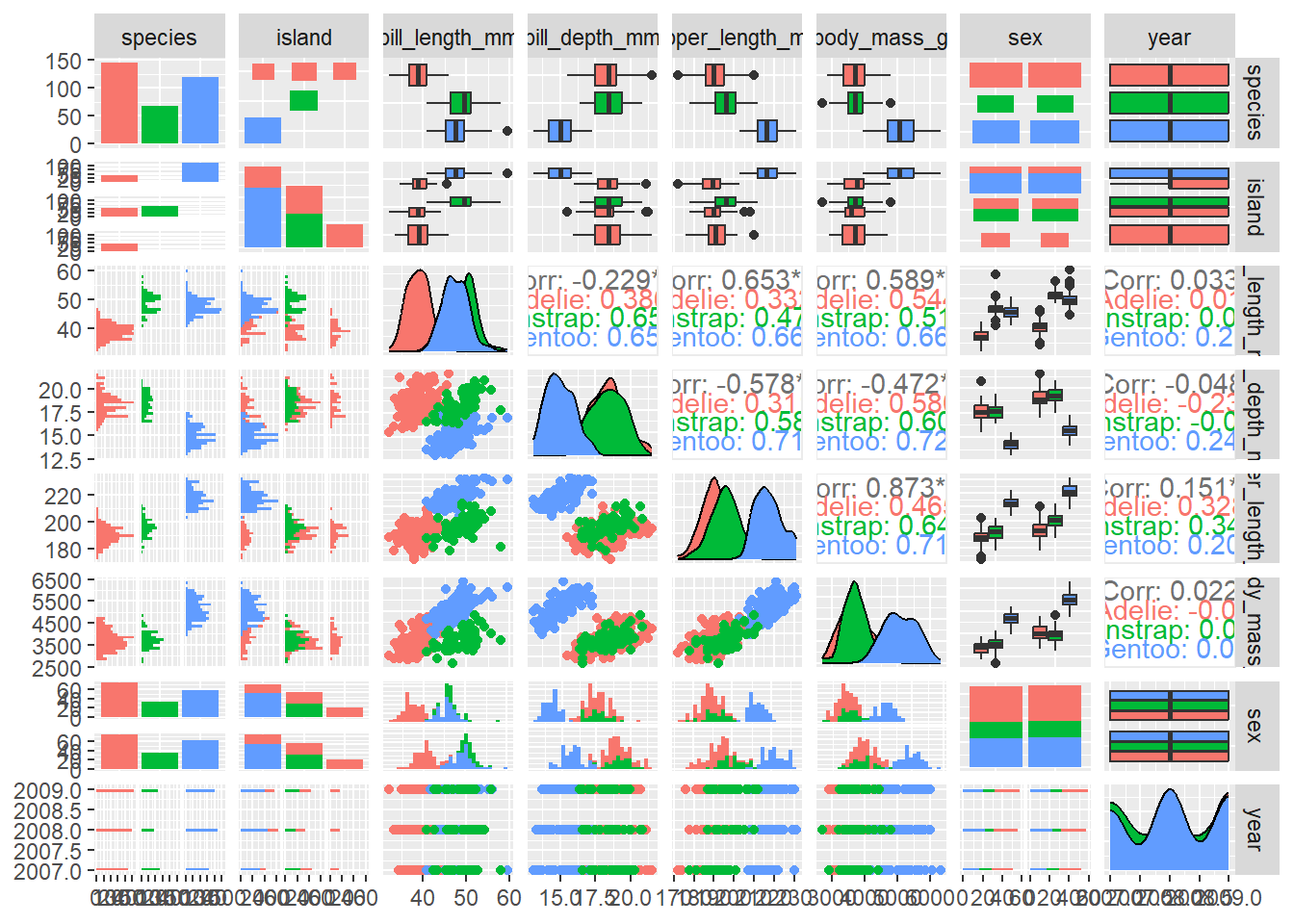
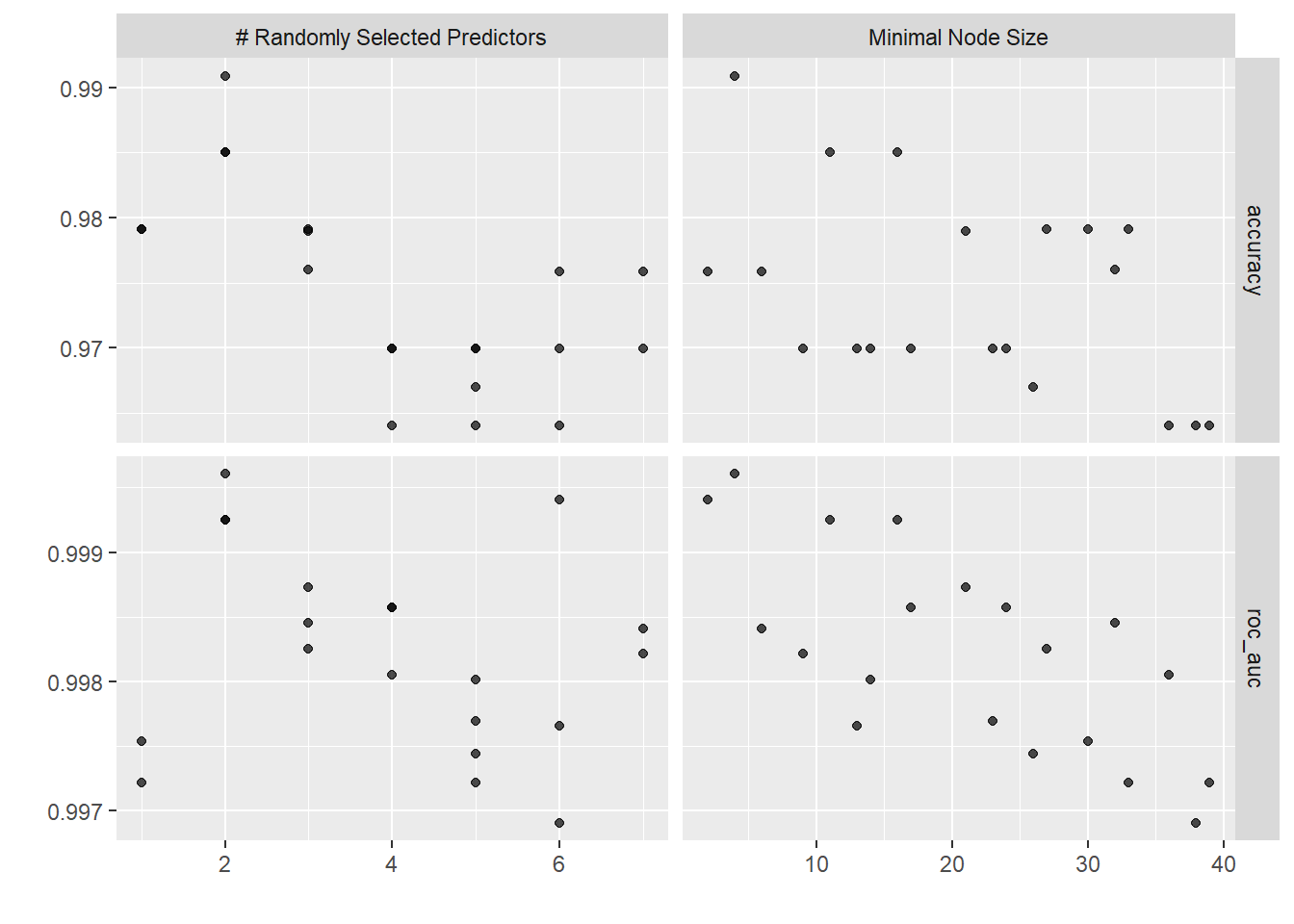
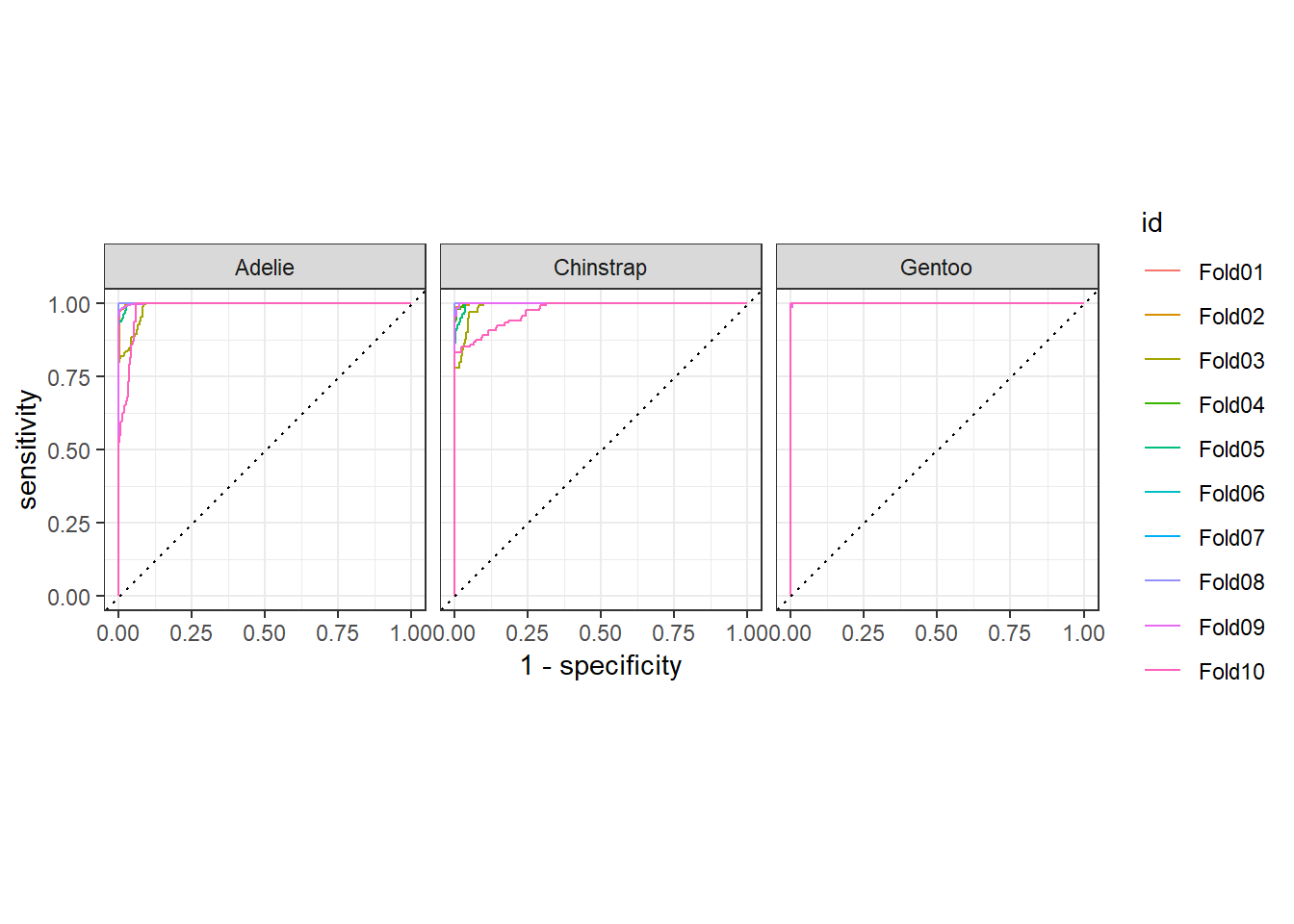
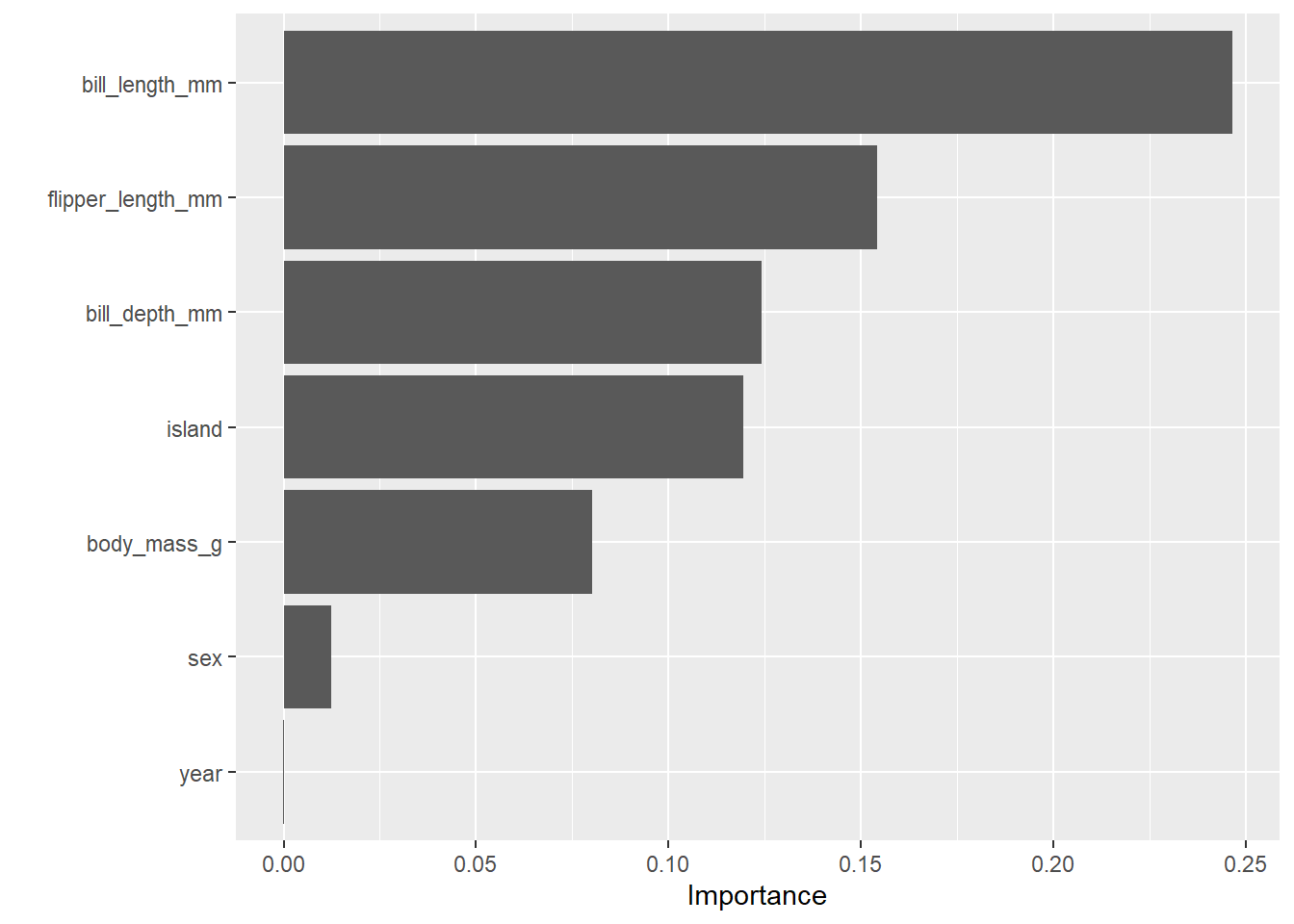
In this blog regarding classification algorithms, we will see about the multiclass random forest model using penguins data. Based on certain features of penguins will try to train a multiclass random forest model and predict the penguin species.
Random Forest is a robust and versatile ensemble learning technique widely employed for both classification and regression tasks. Comprising an ensemble of decision trees, each tree is trained on a bootstrapped sample of the original dataset and considers a random subset of features at each split, mitigating overfitting. The model’s predictions are determined through a majority vote in classification or an average in regression, fostering accuracy and stability. Notably, Random Forest provides insights into feature importance, aiding in the identification of variables contributing significantly to predictive performance. It exhibits resilience against overfitting, particularly due to its feature randomization and bootstrapping mechanisms. Hyperparameter tuning can further enhance the model’s performance, making Random Forest a versatile and powerful tool in machine learning applications.
1. Required libraries
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
### Add formula and model together with workflowtune_wf <-workflow() %>%add_formula(species ~ .) %>%add_model(rf_spec)tune_wf
══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Formula
Model: rand_forest()
── Preprocessor ────────────────────────────────────────────────────────────────
species ~ .
── Model ───────────────────────────────────────────────────────────────────────
Random Forest Model Specification (classification)
Main Arguments:
mtry = tune()
trees = 1000
min_n = tune()
Computational engine: ranger